
Skutočná hodnota nie je v intervale spoľahlivosti. Intervaly spoľahlivosti pre frekvencie a proporcie

Intervaly spoľahlivosti.
Výpočet intervalu spoľahlivosti je založený na priemernej chybe zodpovedajúceho parametra. Interval spoľahlivosti ukazuje, v akých medziach s pravdepodobnosťou (1-a) je skutočná hodnota odhadovaného parametra. Tu a je hladina významnosti, (1-a) sa tiež nazýva hladina spoľahlivosti.
V prvej kapitole sme ukázali, že napríklad pre aritmetický priemer leží skutočný priemer populácie v rámci 2 stredných chýb od priemeru asi 95 % času. Hranice 95 % intervalu spoľahlivosti pre priemer teda budú od priemeru vzorky o dvojnásobok strednej chyby priemeru, t.j. vynásobíme strednú chybu priemeru nejakým faktorom, ktorý závisí od úrovne spoľahlivosti. Pre priemer a rozdiel priemerov sa berie študentský koeficient (kritická hodnota študentského kritéria), pre podiel a rozdiel podielov kritická hodnota z kritéria. Súčin koeficientu a priemernej chyby môžeme nazvať hraničnou chybou tohto parametra, t.j. maximum, ktoré môžeme pri jej hodnotení získať.
Interval spoľahlivosti pre aritmetický priemer : .
Tu je vzorový priemer;
Priemerná chyba aritmetického priemeru;
s- vzorová smerodajná odchýlka;
n
f = n-1 (koeficient študenta).
Interval spoľahlivosti pre rozdiel aritmetických priemerov :
Tu je rozdiel medzi vzorovými prostriedkami;
 - priemerná chyba rozdielu aritmetických priemerov;
- priemerná chyba rozdielu aritmetických priemerov;
s 1, s 2 - vzorové prostriedky štandardné odchýlky;
n1, n2
kritická hodnotaŠtudentov test pre danú hladinu významnosti a a počet stupňov voľnosti f=n1 + n2-2 (koeficient študenta).
Interval spoľahlivosti pre akcií :
![]() .
.
Tu d je podiel vzorky;
– priemerná chyba podielu;
n– veľkosť vzorky (veľkosť skupiny);
Interval spoľahlivosti pre zdieľať rozdiely :
Tu je rozdiel medzi podielmi vzorky;
 je stredná chyba rozdielu medzi aritmetickými priemermi;
je stredná chyba rozdielu medzi aritmetickými priemermi;
n1, n2– veľkosti vzoriek (počet skupín);
Kritická hodnota kritéria z na danej hladine významnosti a ( , , ).
Výpočtom intervalov spoľahlivosti pre rozdiel v ukazovateľoch, po prvé, priamo vidíme možné hodnoty efektu, a nielen jeho bodový odhad. Po druhé, môžeme vyvodiť záver o prijatí alebo vyvrátení nulovej hypotézy a po tretie, môžeme urobiť záver o sile kritéria.
Pri testovaní hypotéz pomocou intervalov spoľahlivosti by sa malo dodržiavať nasledujúce pravidlo:
Ak 100(1-a)-percentný interval spoľahlivosti stredného rozdielu neobsahuje nulu, potom sú rozdiely štatisticky významné na hladine významnosti a; naopak, ak tento interval obsahuje nulu, potom rozdiely nie sú štatisticky významné.
Ak totiž tento interval obsahuje nulu, znamená to, že porovnávaný ukazovateľ môže byť viac alebo menej v jednej zo skupín v porovnaní s druhou, t.j. pozorované rozdiely sú náhodné.
Podľa miesta, kde sa v intervale spoľahlivosti nachádza nula, je možné posúdiť silu kritéria. Ak je nula blízko dolnej alebo hornej hranice intervalu, potom by možno pri väčšom počte porovnávaných skupín rozdiely dosiahli štatistická významnosť. Ak je nula blízko stredu intervalu, znamená to, že zvýšenie aj zníženie ukazovateľa v experimentálnej skupine sú rovnako pravdepodobné a pravdepodobne naozaj neexistujú žiadne rozdiely.
Príklady:
Pre porovnanie chirurgickej úmrtnosti pri použití dvoch rôznych typov anestézie: 61 ľudí bolo operovaných pomocou prvého typu anestézie, 8 zomrelo, pri použití druhého - 67 ľudí, 10 zomrelo.
d 1 \u003d 8/61 \u003d 0,131; d 2 \u003d 10/67 \u003d 0,149; d1-d2 = -0,018.
Rozdiel v letalite porovnávaných metód bude v rozmedzí (-0,018 - 0,122; -0,018 + 0,122) alebo (-0,14; 0,104) s pravdepodobnosťou 100(1-a) = 95 %. Interval obsahuje nulu, t.j. hypotéza o rovnakej úmrtnosti v dvoch odlišné typy narkózu nemožno poprieť.
Úmrtnosť teda môže a bude klesať na 14 % a zvyšovať na 10,4 % s pravdepodobnosťou 95 %, t.j. nula je približne v strede intervalu, takže možno tvrdiť, že s najväčšou pravdepodobnosťou sa tieto dve metódy skutočne nelíšia v letalite.
V príklade, ktorý sme uvažovali vyššie, sa porovnával priemerný čas poklepania v štyroch skupinách študentov, ktoré sa líšili v skóre zo skúšky. Vypočítajme intervaly spoľahlivosti priemerného času lisovania pre študentov, ktorí absolvovali skúšku na 2 a 5 a interval spoľahlivosti pre rozdiel medzi týmito priemermi.
Študentove koeficienty zistíme z tabuliek Studentovho rozdelenia (pozri prílohu): pre prvú skupinu: = t(0,05;48) = 2,011; pre druhú skupinu: = t(0,05;61) = 2,000. Intervaly spoľahlivosti pre prvú skupinu sú teda: = (162,19-2,011*2,18; 162,19+2,011*2,18) = (157,8; 166,6), pre druhú skupinu (156,55- 2,000*1,85) = 156,85*156,0. (152,8; 160,3). Takže pre tých, ktorí zložili skúšku na 2, sa priemerný čas lisovania pohybuje od 157,8 ms do 166,6 ms s pravdepodobnosťou 95%, pre tých, ktorí zložili skúšku na 5 - od 152,8 ms do 160,3 ms s pravdepodobnosťou 95% .
Môžete tiež testovať nulovú hypotézu pomocou intervalov spoľahlivosti pre priemery, nielen pre rozdiel v priemeroch. Napríklad, ako v našom prípade, ak sa intervaly spoľahlivosti pre priemery prekrývajú, nulovú hypotézu nemožno zamietnuť. Aby bolo možné zamietnuť hypotézu na zvolenej hladine významnosti, príslušné intervaly spoľahlivosti sa nesmú prekrývať.
Nájdite interval spoľahlivosti pre rozdiel v priemernom čase lisovania v skupinách, ktoré absolvovali skúšku na 2 a 5. Rozdiel v priemeroch: 162,19 - 156,55 = 5,64. Študentov koeficient: \u003d t (0,05; 49 + 62-2) \u003d t (0,05; 109) \u003d 1,982. Skupinové štandardné odchýlky sa budú rovnať: ; . Vypočítame priemernú chybu rozdielu medzi priemermi:. Interval spoľahlivosti: \u003d (5,64-1,982 * 2,87; 5,64 + 1,982 * 2,87) \u003d (-0,044; 11,33).
Takže rozdiel v priemernom čase lisovania v skupinách, ktoré zložili skúšku v 2 a 5, bude v rozsahu od -0,044 ms do 11,33 ms. Tento interval zahŕňa nulu, t.j. priemerný čas lisovania u tých, ktorí zvládli skúšku s výborným výsledkom, sa môže v porovnaní s tými, ktorí skúšku zložili neuspokojivo, zvýšiť aj znížiť, t.j. nulovú hypotézu nemožno zamietnuť. Ale nula je veľmi blízko spodnej hranice, čas stláčania sa u výborných rozohrávačov skráti oveľa skôr. Môžeme teda konštatovať, že stále existujú rozdiely v priemernom čase kliknutia medzi tými, ktorí prešli o 2 a o 5, len sme ich nedokázali zistiť pre danú zmenu priemerného času, rozptylu priemerného času a veľkosti vzoriek.
Sila testu je pravdepodobnosť zamietnutia nesprávnej nulovej hypotézy, t.j. nájsť rozdiely tam, kde skutočne sú.
Sila testu sa určuje na základe úrovne významnosti, veľkosti rozdielov medzi skupinami, rozptylu hodnôt v skupinách a veľkosti vzorky.
Pre Studentov t-test a analýza rozptylu môžete použiť tabuľky citlivosti.
Sila kritéria môže byť použitá pri predbežnom stanovení požadovaného počtu skupín.
Interval spoľahlivosti ukazuje, v ktorých medziach leží skutočná hodnota odhadovaného parametra s danou pravdepodobnosťou.
Pomocou intervalov spoľahlivosti môžete testovať štatistické hypotézy a vyvodzovať závery o citlivosti kritérií.
LITERATÚRA.
Glantz S. - Kapitola 6.7.
Rebrová O.Yu. - s.112-114, s.171-173, s.234-238.
Sidorenko E. V. - s. 32-33.
Otázky na samoskúšanie žiakov.
1. Aká je sila kritéria?
2. V akých prípadoch je potrebné vyhodnotiť silu kritérií?
3. Metódy výpočtu výkonu.
6. Ako testovať štatistickú hypotézu pomocou intervalu spoľahlivosti?
7. Čo možno povedať o sile kritéria pri výpočte intervalu spoľahlivosti?
Úlohy.
Cieľ– naučiť študentov algoritmy na výpočet intervalov spoľahlivosti štatistických parametrov.
Počas štatistického spracovania údajov by vypočítaný aritmetický priemer, variačný koeficient, korelačný koeficient, rozdielové kritériá a ďalšie bodové štatistiky mali dostať kvantitatívne hranice spoľahlivosti, ktoré naznačujú možné kolísanie ukazovateľa smerom nahor a nadol v rámci intervalu spoľahlivosti.
Príklad 3.1
.
Distribúcia vápnika v krvnom sére opíc, ako už bolo stanovené, je charakterizovaná nasledujúcimi selektívnymi ukazovateľmi: = 11,94 mg%;  = 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (
= 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (  ) s pravdepodobnosťou spoľahlivosti P
= 0,95.
) s pravdepodobnosťou spoľahlivosti P
= 0,95.
Všeobecný priemer je s určitou pravdepodobnosťou v intervale:
 , Kde
, Kde  – vzorový aritmetický priemer; t- študentské kritérium;
– vzorový aritmetický priemer; t- študentské kritérium;  je chyba aritmetického priemeru.
je chyba aritmetického priemeru.
Podľa tabuľky „Hodnoty študentského kritéria“ nájdeme hodnotu
 s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
alebo 11.69  12,19
12,19
S pravdepodobnosťou 95 % teda možno tvrdiť, že všeobecný priemer tohto normálneho rozdelenia je medzi 11,69 a 12,19 mg %.
Príklad 3.2
. Určite hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl (  ) distribúcia vápnika v krvi opíc, ak je známe, že
) distribúcia vápnika v krvi opíc, ak je známe, že  = 1,60, s n
= 100.
= 1,60, s n
= 100.
Na vyriešenie problému môžete použiť nasledujúci vzorec:
Kde  je štatistická chyba rozptylu.
je štatistická chyba rozptylu.
Nájdite chybu rozptylu vzorky pomocou vzorca:  . Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
. Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
Použime vzorec a získame:
alebo 1,38  1,82
1,82
Presnejší interval spoľahlivosti pre všeobecný rozptyl možno zostrojiť pomocou  (chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria
(chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria  na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca
na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca  , pre zvršok
, pre zvršok  . Napríklad pre úroveň dôvery
. Napríklad pre úroveň dôvery  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt
= 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt  s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty
s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty  A
A  . Dostaneme
. Dostaneme  rovná sa 135,80 a
rovná sa 135,80 a  rovná sa 70,06.
rovná sa 70,06.
Ak chcete nájsť hranice spoľahlivosti všeobecného rozptylu pomocou  používame vzorce: pre dolnú hranicu
používame vzorce: pre dolnú hranicu 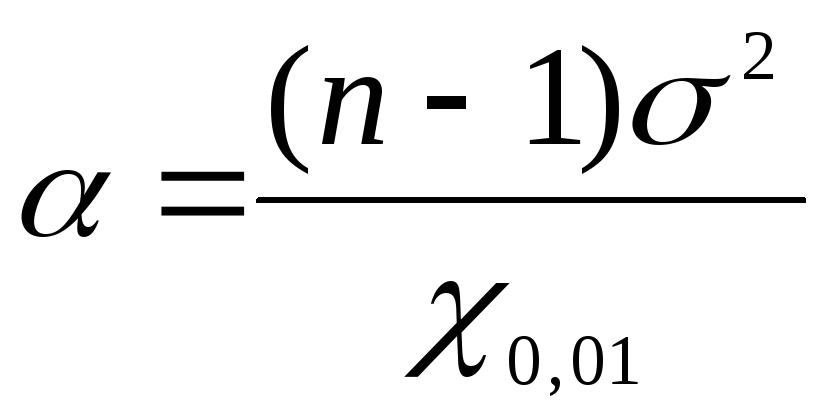 , pre hornú hranicu
, pre hornú hranicu  . Nájdené hodnoty nahraďte údajmi úlohy
. Nájdené hodnoty nahraďte údajmi úlohy  do vzorcov:
do vzorcov:  =
1,17;
=
1,17; = 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
= 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
Príklad 3.3 . Medzi 1000 semenami pšenice z dávky prijatej vo výťahu sa našlo 120 semien infikovaných námeľom. Je potrebné určiť pravdepodobné hranice celkového podielu infikovaných semien v danej partii pšenice.
Hranice spoľahlivosti pre všeobecný podiel pre všetky jeho možné hodnoty by sa mali určiť podľa vzorca:
 ,
,
Kde n je počet pozorovaní; m je absolútne číslo jednej zo skupín; t je normalizovaná odchýlka.
Frakcia vzorky infikovaných semien sa rovná  alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
 )t
= 1,960.
)t
= 1,960.
Dostupné údaje dosadíme do vzorca:
Preto sú hranice intervalu spoľahlivosti  = 0,122–0,041 = 0,081 alebo 8,1 %;
= 0,122–0,041 = 0,081 alebo 8,1 %;  = 0,122 + 0,041 = 0,163 alebo 16,3 %.
= 0,122 + 0,041 = 0,163 alebo 16,3 %.
S hladinou spoľahlivosti 95 % možno teda konštatovať, že celkový podiel infikovaných semien sa pohybuje medzi 8,1 a 16,3 %.
Príklad 3.4 . Variačný koeficient, ktorý charakterizuje variáciu vápnika (mg %) v krvnom sére opíc, bol rovný 10,6 %. Veľkosť vzorky n= 100. Je potrebné určiť hranice 95 % intervalu spoľahlivosti pre všeobecný parameter životopis.
Hranice spoľahlivosti pre všeobecný variačný koeficient životopis sa určujú podľa nasledujúcich vzorcov:
 A
A  , Kde K
medzihodnota vypočítaná podľa vzorca
, Kde K
medzihodnota vypočítaná podľa vzorca  .
.
Vedieť to s mierou sebadôvery R= 95 % normalizovaná odchýlka (Studentov t-test pre k
=
 )t
= 1,960, vopred vypočítajte hodnotu KOMU:
)t
= 1,960, vopred vypočítajte hodnotu KOMU:
 .
.
 alebo 9,3 %
alebo 9,3 %
 alebo 12,3 %
alebo 12,3 %
Všeobecný variačný koeficient s pravdepodobnosťou spoľahlivosti 95 % teda leží v rozsahu od 9,3 do 12,3 %. Pri opakovaných vzorkách variačný koeficient nepresiahne 12,3 % a neklesne pod 9,3 % v 95 prípadoch zo 100.
Otázky na sebaovládanie:

Úlohy na samostatné riešenie.
1. Priemerné percento tuku v mlieku na laktáciu kráv krížencov Kholmogory bolo nasledovné: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Nastavte intervaly spoľahlivosti pre celkový priemer na úrovni spoľahlivosti 95 % (20 bodov).
2. Na 400 rastlinách hybridnej raže sa prvé kvety objavili v priemere 70,5 dňa po zasiatí. Štandardná odchýlka bola 6,9 dňa. Určte chybu priemeru a intervalov spoľahlivosti pre priemer populácie a rozptyl na hladine významnosti W= 0,05 a W= 0,01 (25 bodov).
3. Pri štúdiu dĺžky listov 502 exemplárov záhradných jahôd sa získali tieto údaje:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
\u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
4. Pri skúmaní 150 dospelých mužov bola priemerná výška 167 cm, a σ \u003d 6 cm. Aké sú hranice všeobecného priemeru a všeobecného rozptylu s pravdepodobnosťou spoľahlivosti 0,99 a 0,95? (25 bodov).
5. Distribúciu vápnika v krvnom sére opíc charakterizujú tieto selektívne ukazovatele:
 = 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
= 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
6. Bol skúmaný všeobecný obsah dusíka v krvnej plazme potkanov albínov vo veku 37 a 180 dní. Výsledky sú vyjadrené v gramoch na 100 cm3 plazmy. Vo veku 37 dní malo 9 potkanov: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Vo veku 180 dní malo 8 potkanov: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Nastavte intervaly spoľahlivosti pre rozdiel s úrovňou spoľahlivosti 0,95 (50 bodov).
7. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie vápnika (mg %) v krvnom sére opíc, ak pre toto rozdelenie je veľkosť vzorky n = 100, štatistická chyba rozptylu vzorky s σ 2 = 1,60 (40 bodov).
8. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie 40 kláskov pšenice po dĺžke (σ 2 = 40,87 mm 2). (25 bodov).
9. Fajčenie sa považuje za hlavný predisponujúci faktor k obštrukčnej chorobe pľúc. Pasívne fajčenie sa za takýto faktor nepovažuje. Vedci pochybovali o neškodnosti pasívneho fajčenia a skúmali jeho priechodnosť dýchacieho traktu u nefajčiarov, pasívnych a aktívnych fajčiarov. Na charakterizáciu stavu dýchacieho traktu sa vzal jeden z ukazovateľov funkcie vonkajšie dýchanie je maximálny stredný výdychový prietok. Zníženie tohto indikátora je znakom zhoršenej priechodnosti dýchacích ciest. Údaje z prieskumu sú uvedené v tabuľke.
|
Počet vyšetrených |
Maximálny stredný výdychový prietok, l/s |
||
|
Smerodajná odchýlka |
|||
|
Nefajčiari |
|||
|
práca v nefajčiarskom priestore | |||
|
pracovať v zadymenej miestnosti | |||
|
fajčiarov |
|||
|
fajčiari nie veľké číslo cigarety | |||
|
priemerný počet fajčiarov cigariet | |||
|
fajčenie veľkého množstva cigariet | |||
V tabuľke nájdite 95 % intervaly spoľahlivosti pre všeobecný priemer a všeobecný rozptyl pre každú zo skupín. Aké sú rozdiely medzi skupinami? Výsledky prezentujte graficky (25 bodov).
10. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný rozptyl počtu prasiatok v 64 pôrodoch, ak štatistická chyba rozptylu vzorky s σ 2 = 8,25 (30 bodov).
11. Je známe, že priemerná hmotnosť králikov je 2,1 kg. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný priemer a rozptyl kedy n= 30, σ = 0,56 kg (25 bodov).
12. V 100 klasoch sa meral obsah zrna v klase ( X), dĺžka hrotu ( Y) a hmotnosť zrna v klase ( Z). Nájdite intervaly spoľahlivosti pre všeobecný priemer a rozptyl pre P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 ak
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
13. Náhodne vybraných 100 uší ozimná pšenica bol spočítaný počet kláskov. Súbor vzoriek bol charakterizovaný nasledujúcimi ukazovateľmi:
 = 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (
= 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (  ) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
14. Počet rebier na schránkach fosílneho mäkkýša Ortambonity kaligrama:
To je známe n = 19, σ = 4,25. Určte hranice intervalu spoľahlivosti pre všeobecný priemer a všeobecný rozptyl na hladine významnosti W = 0,01 (25 bodov).
15. Na stanovenie dojivosti na komerčnej mliečnej farme bola denne stanovená úžitkovosť 15 kráv. Podľa údajov za rok dala každá krava v priemere za deň nasledovné množstvo mlieka (l): 22; 19; 25; 20; 27; 17; tridsať; 21; 18; 24; 26; 23; 25; 20; 24. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Môžeme očakávať priemernú ročnú dojivosť na kravu 10 000 litrov? (50 bodov).
16. Za účelom zistenia priemernej úrody pšenice na farme bola vykonaná kosba na vzorových pozemkoch o výmere 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 a 2 ha. Úroda (c/ha) z pozemkov bola 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 resp. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Dá sa očakávať, že priemerná úroda poľnohospodárskeho podniku bude 42 c/ha? (50 bodov).
Interval spoľahlivosti pre matematické očakávania je interval vypočítaný z údajov, ktoré obsahujú so známou pravdepodobnosťou očakávaná hodnota populácia. Prirodzeným odhadom matematického očakávania je aritmetický priemer jeho pozorovaných hodnôt. Preto budeme ďalej počas hodiny používať pojmy „priemer“, „priemerná hodnota“. Pri problémoch s výpočtom intervalu spoľahlivosti sa najčastejšie vyžaduje odpoveď „Interval spoľahlivosti priemerného čísla [hodnota v konkrétnom probléme] je od [menšia hodnota] do [ väčšiu hodnotu]". Pomocou intervalu spoľahlivosti môžete vyhodnotiť nielen priemerné hodnoty, ale aj podiel jedného alebo druhého znaku vo všeobecnej populácii. Priemerné hodnoty, rozptyl, smerodajnú odchýlku a chybu, cez ktoré sa dostaneme k novým definíciám a vzorce, boli analyzované v lekcii Charakteristika vzorky a populácie .
Bodové a intervalové odhady priemeru
Ak sa priemerná hodnota bežnej populácie odhaduje číslom (bodom), tak pre odhad neznáma stredná veľkosť všeobecnej populácie sa berie špecifický priemer, ktorý sa vypočíta zo vzorky pozorovaní. V tomto prípade je stredná hodnota vzorky náhodná premenná- sa nezhoduje s priemernou hodnotou bežnej populácie. Preto pri uvádzaní strednej hodnoty vzorky je potrebné súčasne uviesť aj výberovú chybu. Štandardná chyba sa používa ako miera vzorkovacej chyby, ktorá je vyjadrená v rovnakých jednotkách ako priemer. Preto sa často používa tento zápis: .
Ak sa vyžaduje, aby bol odhad priemeru spojený s určitou pravdepodobnosťou, potom sa parameter všeobecnej záujmovej populácie musí odhadnúť nie jedným číslom, ale intervalom. Interval spoľahlivosti je interval, v ktorom s určitou pravdepodobnosťou P zistí sa hodnota odhadovaného ukazovateľa bežnej populácie. Interval spoľahlivosti, v ktorom s pravdepodobnosťou P = 1 - α je náhodná premenná, vypočíta sa takto:
![]() ,
,
α = 1 - P, ktorý nájdete v prílohe takmer každej knihy o štatistike.
V praxi nie je známy priemer a rozptyl populácie, takže rozptyl populácie je nahradený rozptylom vzorky a priemer populácie priemerom vzorky. Interval spoľahlivosti sa teda vo väčšine prípadov vypočíta takto:
![]() .
.
Vzorec intervalu spoľahlivosti možno použiť na odhad priemernej hodnoty populácie, ak
- štandardná odchýlka všeobecnej populácie je známa;
- alebo štandardná odchýlka populácie nie je známa, ale veľkosť vzorky je väčšia ako 30.
Priemer vzorky je nezaujatý odhad priemeru populácie. Na druhej strane, rozptyl vzorky  nie je nezaujatým odhadom rozptylu populácie . Na získanie nestranného odhadu rozptylu populácie vo vzorci rozptylu vzorky je veľkosť vzorky n by mal byť nahradený n-1.
nie je nezaujatým odhadom rozptylu populácie . Na získanie nestranného odhadu rozptylu populácie vo vzorci rozptylu vzorky je veľkosť vzorky n by mal byť nahradený n-1.
Príklad 1 Zo 100 náhodne vybraných kaviarní v určitom meste sa zbierajú informácie, že priemerný počet zamestnancov v nich je 10,5 so štandardnou odchýlkou 4,6. Určte interval spoľahlivosti 95 % počtu zamestnancov kaviarne.
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
95 % interval spoľahlivosti pre priemerný počet zamestnancov kaviarní bol teda medzi 9,6 a 11,4.
Príklad 2 Pre náhodnú vzorku zo všeobecnej populácie 64 pozorovaní boli vypočítané tieto celkové hodnoty:
súčet hodnôt v pozorovaniach,
súčet štvorcových odchýlok hodnôt od priemeru ![]() .
.
Vypočítajte 95 % interval spoľahlivosti pre očakávanú hodnotu.
vypočítajte štandardnú odchýlku:
 ,
,
vypočítajte priemernú hodnotu:
![]() .
.
Interval spoľahlivosti nahraďte hodnotami vo výraze:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
Dostaneme:
95 % interval spoľahlivosti pre matematické očakávanie tejto vzorky sa teda pohyboval od 7,484 do 11,266.
Príklad 3 Pre náhodnú vzorku zo všeobecnej populácie 100 pozorovaní bola vypočítaná stredná hodnota 15,2 a štandardná odchýlka 3,2. Vypočítajte 95 % interval spoľahlivosti pre očakávanú hodnotu a potom 99 % interval spoľahlivosti. Ak výkon vzorky a jej variácie zostanú rovnaké, ale faktor spoľahlivosti sa zvýši, bude sa interval spoľahlivosti zužovať alebo rozširovať?
Tieto hodnoty dosadíme do výrazu pre interval spoľahlivosti:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
Dostaneme:
![]() .
.
95 % interval spoľahlivosti pre priemer tejto vzorky bol teda od 14,57 do 15,82.
Opäť dosadíme tieto hodnoty do výrazu pre interval spoľahlivosti:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,01 .
Dostaneme:
![]() .
.
99 % interval spoľahlivosti pre priemer tejto vzorky bol teda od 14,37 do 16,02.
Ako vidíte, so zvyšujúcim sa faktorom spoľahlivosti sa zvyšuje aj kritická hodnota štandardného normálneho rozdelenia, a preto sú začiatočné a koncové body intervalu umiestnené ďalej od priemeru, a teda intervalu spoľahlivosti pre matematické očakávania. zvyšuje.
Bodové a intervalové odhady špecifickej hmotnosti
Podiel niektorého znaku vzorky možno interpretovať ako bodový odhad podielu p rovnaká vlastnosť v bežnej populácii. Ak je potrebné túto hodnotu spájať s pravdepodobnosťou, potom by sa mal vypočítať interval spoľahlivosti špecifickej hmotnosti p v bežnej populácii s pravdepodobnosťou P = 1 - α :
 .
.
Príklad 4 V určitom meste sú dvaja kandidáti A A B kandidovať na primátora. Náhodne opýtaných bolo 200 obyvateľov mesta, z ktorých 46 % odpovedalo, že by volili kandidáta A, 26 % - pre kandidáta B a 28 % nevie, koho budú voliť. Určte 95 % interval spoľahlivosti pre podiel obyvateľov mesta, ktorí podporujú kandidáta A.
Intervaly spoľahlivosti ( Angličtina Intervaly spoľahlivosti) jeden z typov intervalových odhadov používaných v štatistike, ktoré sú vypočítané pre danú hladinu významnosti. Umožňujú tvrdenie, že skutočná hodnota neznáma štatistický parameter bežnej populácie sa nachádza v získanom rozmedzí hodnôt s pravdepodobnosťou, ktorá je daná zvolenou hladinou štatistickej významnosti.
Normálne rozdelenie
Keď je známy rozptyl (σ 2 ) populácie údajov, z-skóre sa môže použiť na výpočet hraníc spoľahlivosti (hraničné body intervalu spoľahlivosti). V porovnaní s použitím t-distribúcie, použitie z-skóre poskytne nielen užší interval spoľahlivosti, ale poskytne aj spoľahlivejšie odhady priemeru a štandardnej odchýlky (σ), keďže Z-skóre je založené na normálnom rozdelení.
Vzorec
Na určenie hraničných bodov intervalu spoľahlivosti za predpokladu, že je známa štandardná odchýlka súboru údajov, sa používa nasledujúci vzorec
| L = X - Za/2 | σ |
| √n |
Príklad
Predpokladajme, že veľkosť vzorky je 25 pozorovaní, priemer vzorky je 15 a štandardná odchýlka populácie je 8. Pre hladinu významnosti α=5% je Z-skóre Zα/2=1,96. V tomto prípade bude dolná a horná hranica intervalu spoľahlivosti
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Môžeme teda konštatovať, že s pravdepodobnosťou 95 % bude matematické očakávanie bežnej populácie spadať do intervalu od 11,864 do 18,136.
Metódy na zúženie intervalu spoľahlivosti
Povedzme, že rozsah je príliš široký na účely našej štúdie. Existujú dva spôsoby, ako znížiť rozsah intervalu spoľahlivosti.
- Znížte hladinu štatistickej významnosti α.
- Zväčšite veľkosť vzorky.
Znížením hladiny štatistickej významnosti na α=10% dostaneme Z-skóre rovné Z α/2 =1,64. V tomto prípade bude dolná a horná hranica intervalu
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
A samotný interval spoľahlivosti možno zapísať ako
V tomto prípade môžeme predpokladať, že s pravdepodobnosťou 90 % budú matematické očakávania všeobecnej populácie spadať do tohto rozsahu.
Ak chceme zachovať hladinu štatistickej významnosti α, tak jedinou alternatívou je zväčšiť veľkosť vzorky. Zvýšením na 144 pozorovaní získame nasledujúce hodnoty hraníc spoľahlivosti
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Samotný interval spoľahlivosti bude vyzerať takto:
Zúženie intervalu spoľahlivosti bez zníženia úrovne štatistickej významnosti je teda možné len zväčšením veľkosti vzorky. Ak nie je možné zväčšiť veľkosť vzorky, tak zúženie intervalu spoľahlivosti možno dosiahnuť výlučne znížením hladiny štatistickej významnosti.
Vytvorenie intervalu spoľahlivosti pre nenormálne rozdelenie
Ak smerodajná odchýlka populácia nie je známa alebo rozdelenie nie je normálne, t-distribúcia sa používa na vytvorenie intervalu spoľahlivosti. Táto technika je konzervatívnejšia, čo je vyjadrené v širších intervaloch spoľahlivosti v porovnaní s technikou založenou na Z-skóre.
Vzorec
Na výpočet dolnej a hornej hranice intervalu spoľahlivosti na základe t-distribúcie sa používajú nasledujúce vzorce
| L = X - ta | σ |
| √n |
Študentovo rozdelenie alebo t-rozdelenie závisí iba od jedného parametra - počtu stupňov voľnosti, ktorý sa rovná počtu hodnôt jednotlivých znakov (počet pozorovaní vo vzorke). Hodnotu Studentovho t-testu pre daný počet stupňov voľnosti (n) a hladinu štatistickej významnosti α možno nájsť vo vyhľadávacích tabuľkách.
Príklad
Predpokladajme, že veľkosť vzorky je 25 individuálnych hodnôt, priemerná hodnota vzorky je 50 a štandardná odchýlka vzorky je 28. Musíte zostrojiť interval spoľahlivosti pre hladinu štatistickej významnosti α=5 %.
V našom prípade je počet stupňov voľnosti 24 (25-1), preto zodpovedajúca tabuľková hodnota Studentovho t-testu pre hladinu štatistickej významnosti α=5 % je 2,064. Preto budú dolné a horné hranice intervalu spoľahlivosti
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
A samotný interval môže byť napísaný ako
Môžeme teda konštatovať, že s pravdepodobnosťou 95 % bude matematické očakávanie bežnej populácie v rozmedzí.
Použitie t-distribúcie vám umožňuje zúžiť interval spoľahlivosti buď znížením štatistickej významnosti alebo zvýšením veľkosti vzorky.
Znížením štatistickej významnosti z 95 % na 90 % v podmienkach nášho príkladu dostaneme zodpovedajúcu tabuľkovú hodnotu Studentovho t-testu 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
V tomto prípade môžeme povedať, že s pravdepodobnosťou 90 % budú matematické očakávania bežnej populácie v rozmedzí.
Ak nechceme znížiť štatistickú významnosť, tak jedinou alternatívou je zväčšiť veľkosť vzorky. Povedzme, že ide o 64 jednotlivých pozorovaní a nie 25 ako v počiatočnej podmienke príkladu. Tabuľková hodnota Studentovho t-testu pre 63 stupňov voľnosti (64-1) a hladina štatistickej významnosti α=5 % je 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
To nám dáva príležitosť tvrdiť, že s pravdepodobnosťou 95 % budú matematické očakávania všeobecnej populácie v rozmedzí.
Veľké vzorky
Veľké vzorky sú vzorky z populácie údajov s viac ako 100 individuálnymi pozorovaniami. Štatistické štúdie ukázali, že väčšie vzorky majú tendenciu byť normálne rozdelené, aj keď rozdelenie populácie nie je normálne. Okrem toho pri takýchto vzorkách poskytuje použitie z-skóre a t-distribúcie približne rovnaké výsledky pri konštrukcii intervalov spoľahlivosti. Pre veľké vzorky je teda prijateľné použiť z-skóre pre normálnu distribúciu namiesto t-distribúcie.
Zhrnutie
Odhad intervalov spoľahlivosti
Učebné ciele
Štatistiky zohľadňujú nasledovné dve hlavné úlohy:
Máme nejaký odhad založený na vzorových údajoch a chceme urobiť nejaké pravdepodobnostné vyhlásenie o tom, kde je skutočná hodnota odhadovaného parametra.
Máme konkrétnu hypotézu, ktorú je potrebné otestovať na základe vzorových údajov.
V tejto téme uvažujeme o prvom probléme. Zavádzame aj definíciu intervalu spoľahlivosti.
Interval spoľahlivosti je interval, ktorý je vytvorený okolo odhadovanej hodnoty parametra a ukazuje, kde leží skutočná hodnota odhadovaného parametra s a priori danou pravdepodobnosťou.
Po preštudovaní materiálu na túto tému:
zistiť, aký je interval spoľahlivosti odhadu;
naučiť sa klasifikovať štatistické problémy;
Zistite, ako vytvoriť intervaly spoľahlivosti štatistické vzorce a pomocou softvérových nástrojov;
naučiť sa určovať požadované veľkosti vzoriek na dosiahnutie určitých parametrov presnosti štatistických odhadov.
Rozdelenie charakteristík vzorky
T-distribúcia
Ako bolo uvedené vyššie, rozdelenie náhodnej premennej je blízke štandardizovanému normálnemu rozdeleniu s parametrami 0 a 1. Keďže nepoznáme hodnotu σ, nahradíme ju nejakým odhadom s . Množstvo má už iné rozdelenie, a to, príp Študentská distribúcia, ktorý je určený parametrom n -1 (počet stupňov voľnosti). Toto rozdelenie je blízke normálnemu rozdeleniu (čím väčšie n, tým bližšie sú rozdelenia).
Na obr. 95  Prezentuje sa študentské rozdelenie s 30 stupňami voľnosti. Ako vidíte, je veľmi blízko normálnemu rozdeleniu.
Prezentuje sa študentské rozdelenie s 30 stupňami voľnosti. Ako vidíte, je veľmi blízko normálnemu rozdeleniu.
Podobne ako funkcie pre prácu s normálnym rozdelením NORMDIST a NORMINV existujú funkcie pre prácu s t-rozdelením - STUDIST (TDIST) a STUDRASPBR (TINV). Príklad použitia týchto funkcií nájdete v súbore STUDRIST.XLS (šablóna a riešenie) a na obr. 96  .
.
Rozdelenie iných charakteristík
Ako už vieme, na určenie presnosti odhadu očakávania potrebujeme t-distribúciu. Na odhad iných parametrov, ako je rozptyl, sú potrebné iné rozdelenia. Dve z nich sú F-distribúcia a x 2 -distribúcia.
Interval spoľahlivosti pre priemer
Interval spoľahlivosti je interval, ktorý je vytvorený okolo odhadovanej hodnoty parametra a ukazuje, kde leží skutočná hodnota odhadovaného parametra s apriórne danou pravdepodobnosťou.
Nastáva konštrukcia intervalu spoľahlivosti pre strednú hodnotu nasledujúcim spôsobom:
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby mohol manažér odhadnúť dopyt po ňom, plánuje náhodne vybrať 40 návštevníkov spomedzi tých, ktorí ho už vyskúšali, a požiadať ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný počet bodov, ktoré získajú Nový produkt a zostrojte 95 % interval spoľahlivosti pre tento odhad. Ako to spraviť? (pozri súbor SANDWICH1.XLS (šablóna a riešenie).
Riešenie
Na vyriešenie tohto problému môžete použiť . Výsledky sú uvedené na obr. 97  .
.
Interval spoľahlivosti pre celkovú hodnotu
Niekedy je podľa vzorových údajov potrebné odhadnúť nie matematické očakávanie, ale celkový súčet hodnôt. Napríklad v situácii s audítorom môže byť zaujímavé odhadnúť nie priemernú hodnotu faktúry, ale súčet všetkých faktúr.
Nech N je celkový počet prvkov, n je veľkosť vzorky, T3 je súčet hodnôt vo vzorke, T" je odhad súčtu za celú populáciu, potom ![]() a interval spoľahlivosti sa vypočíta podľa vzorca , kde s je odhad štandardnej odchýlky pre vzorku, je odhad priemeru pre vzorku.
a interval spoľahlivosti sa vypočíta podľa vzorca , kde s je odhad štandardnej odchýlky pre vzorku, je odhad priemeru pre vzorku.
Príklad
Povedzme, že daňový úrad chce odhadnúť výšku celkových vrátených daní pre 10 000 daňovníkov. Daňovník buď dostane refundáciu, alebo zaplatí dodatočné dane. Nájdite 95 % interval spoľahlivosti pre vrátenú sumu za predpokladu, že veľkosť vzorky je 500 ľudí (pozri súbor REFUND AMOUNT.XLS (šablóna a riešenie).
Riešenie
V programe StatPro neexistuje pre tento prípad žiadny špeciálny postup, môžete však vidieť, že hranice možno získať z hraníc pre priemer pomocou vyššie uvedených vzorcov (obr. 98  ).
).
Interval spoľahlivosti pre pomer
Nech p je očakávaný podiel zákazníkov a pv je odhad tohto podielu získaný zo vzorky veľkosti n. Dá sa ukázať, že pre dostatočne veľké  distribúcia odhadu bude blízko normálu so strednou hodnotou p a štandardnou odchýlkou
distribúcia odhadu bude blízko normálu so strednou hodnotou p a štandardnou odchýlkou ![]() . Štandardná chyba odhadu je v tomto prípade vyjadrená ako
. Štandardná chyba odhadu je v tomto prípade vyjadrená ako  a interval spoľahlivosti ako
a interval spoľahlivosti ako  .
.
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby manažér odhadol dopyt po ňom, náhodne vybral 40 návštevníkov spomedzi tých, ktorí ho už vyskúšali a požiadal ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný podiel zákazníkov, ktorí ohodnotia nový produkt aspoň 6 bodmi (očakáva, že títo zákazníci budú spotrebiteľmi nového produktu).
Riešenie
Na začiatku vytvoríme nový stĺpec na základe 1, ak skóre klienta bolo viac ako 6 bodov a 0 v opačnom prípade (pozri súbor SANDWICH2.XLS (šablóna a riešenie).
Metóda 1
Počítaním sumy 1 odhadneme podiel a potom použijeme vzorce.
Hodnota z cr je prevzatá zo špeciálnych tabuliek normálneho rozdelenia (napríklad 1,96 pre 95 % interval spoľahlivosti).
Použitím tohto prístupu a konkrétnych údajov na vytvorenie 95% intervalu dostaneme nasledujúce výsledky(Obr. 99  ). Kritická hodnota parametra z cr je 1,96. Štandardná chyba odhadu je 0,077. Dolná hranica intervalu spoľahlivosti je 0,475. Horná hranica intervalu spoľahlivosti je 0,775. Manažér teda môže s 95 % istotou predpokladať, že percento zákazníkov, ktorí ohodnotia nový produkt 6 a viac bodov, bude medzi 47,5 a 77,5.
). Kritická hodnota parametra z cr je 1,96. Štandardná chyba odhadu je 0,077. Dolná hranica intervalu spoľahlivosti je 0,475. Horná hranica intervalu spoľahlivosti je 0,775. Manažér teda môže s 95 % istotou predpokladať, že percento zákazníkov, ktorí ohodnotia nový produkt 6 a viac bodov, bude medzi 47,5 a 77,5.
Metóda 2
Tento problém je možné vyriešiť pomocou štandardných nástrojov StatPro. Na tento účel stačí poznamenať, že podiel sa v tomto prípade zhoduje s priemernou hodnotou stĺpca Typ. Ďalej aplikujte StatPro/štatistická inferencia/analýza jednej vzorky na vytvorenie intervalu spoľahlivosti pre strednú hodnotu (odhad očakávania) pre stĺpec Typ. Výsledky získané v tomto prípade budú veľmi blízke výsledkom 1. metódy (obr. 99).
Interval spoľahlivosti pre štandardnú odchýlku
s sa používa ako odhad štandardnej odchýlky (vzorec je uvedený v časti 1). Funkcia hustoty odhadu s je funkcia chí-kvadrát, ktorá má podobne ako t-rozdelenie n-1 stupňov voľnosti. Pre prácu s touto distribúciou existujú špeciálne funkcie CHI2DIST (CHIDIST) a CHI2OBR (CHIINV) .
Interval spoľahlivosti v tomto prípade už nebude symetrický. Podmienená schéma hraníc je znázornená na obr. 100 .
Príklad
Stroj by mal vyrábať diely s priemerom 10 cm.Vplyvom rôznych okolností však dochádza k chybám. Kontrolór kvality sa obáva dvoch vecí: po prvé, priemerná hodnota by mala byť 10 cm; po druhé, aj v tomto prípade, ak sú odchýlky veľké, mnohé detaily budú zamietnuté. Každý deň vyrobí vzorku 50 dielov (pozri súbor KONTROLA KVALITY.XLS (šablóna a riešenie). Aké závery môže takáto vzorka poskytnúť?
Riešenie
Konštruujeme 95 % intervaly spoľahlivosti pre priemer a pre štandardnú odchýlku pomocou StatPro/Štatistická inferencia/ Analýza jednej vzorky(Obr. 101  ).
).
Ďalej, za predpokladu normálneho rozdelenia priemerov, vypočítame podiel chybných výrobkov, pričom nastavíme maximálnu odchýlku 0,065. Pomocou možností vyhľadávacej tabuľky (prípad dvoch parametrov) zostrojíme závislosť percenta zmetkov od strednej hodnoty a smerodajnej odchýlky (obr. 102  ).
).
Interval spoľahlivosti pre rozdiel dvoch priemerov
Toto je jedna z najviac dôležité aplikácieštatistické metódy. Príklady situácie.
Vedúci obchodu s odevmi by rád vedel, koľko viac alebo menej minie priemerná nakupujúca žena v obchode ako muž.
Obe letecké spoločnosti lietajú na podobných trasách. Spotrebiteľská organizácia by chcela porovnať rozdiel medzi priemerným očakávaným meškaním letu pre obe letecké spoločnosti.
Spoločnosť posiela kupóny na určité typy tovar v jednom meste a neposiela do iného. Manažéri chcú porovnať priemerné nákupy týchto položiek počas nasledujúcich dvoch mesiacov.
Predajca áut často rieši manželské páry na prezentáciách. Aby sme porozumeli ich osobným reakciám na prezentáciu, páry často vedú rozhovory oddelene. Manažér chce zhodnotiť rozdiel v hodnotení u mužov a žien.
Prípad nezávislých vzoriek
Stredný rozdiel bude mať t-distribúciu s n 1 + n 2 - 2 stupňami voľnosti. Interval spoľahlivosti pre μ 1 - μ 2 je vyjadrený pomerom:

Tento problém možno vyriešiť nielen vyššie uvedenými vzorcami, ale aj štandardnými nástrojmi StatPro. K tomu stačí podať žiadosť
Interval spoľahlivosti pre rozdiel medzi proporciami
Nech sú matematické očakávania akcií. Nech sú ich vzorové odhady postavené na vzorkách veľkosti n 1 a n 2, v tomto poradí. Potom je uvedený odhad rozdielu. Preto je interval spoľahlivosti pre tento rozdiel vyjadrený ako:
Tu z cr je hodnota získaná z normálneho rozdelenia špeciálnych tabuliek (napríklad 1,96 pre 95 % interval spoľahlivosti).
Smerodajná chyba odhadu je v tomto prípade vyjadrená vzťahom:
 .
.
Príklad
Obchod v rámci prípravy na veľký výpredaj podnikol tieto kroky: marketingový výskum. Vybraných 300 najlepších kupujúcich bolo náhodne rozdelených do dvoch skupín po 150 členoch. Všetkým vybraným kupujúcim boli zaslané pozvánky na účasť na predaji, avšak len pre členov prvej skupiny bol priložený kupón s právom na zľavu 5 %. Pri predaji boli zaznamenané nákupy všetkých 300 vybraných kupujúcich. Ako môže manažér interpretovať výsledky a urobiť úsudok o efektívnosti kupónovania? (Pozri súbor COUPONS.XLS (šablóna a riešenie)).
Riešenie
Pre náš konkrétny prípad zo 150 zákazníkov, ktorí dostali zľavový kupón, 55 nakúpilo vo výpredaji a spomedzi 150, ktorí kupón nedostali, nakúpilo iba 35 (obr. 103  ). Potom sú hodnoty podielov vzorky 0,3667 a 0,2333. A rozdiel vzorky medzi nimi je rovný 0,1333, resp. Za predpokladu intervalu spoľahlivosti 95 % zistíme z tabuľky normálneho rozdelenia z cr = 1,96. kalkulácia štandardná chyba rozdiel vzorky je 0,0524. Nakoniec dostaneme, že spodná hranica 95% intervalu spoľahlivosti je 0,0307 a horná hranica je 0,2359. Získané výsledky možno interpretovať tak, že na každých 100 zákazníkov, ktorí získali zľavový kupón, môžeme očakávať od 3 do 23 nových zákazníkov. Treba však mať na pamäti, že tento záver sám o sebe neznamená efektívnosť využitia kupónov (pretože poskytnutím zľavy prichádzame o zisk!). Ukážme si to na konkrétnych údajoch. Predstierajme to priemerná veľkosť nákup je 400 rubľov, z toho 50 rubľov. je tam zisk obchodu. Potom sa očakávaný zisk na 100 zákazníkov, ktorí nedostali kupón, rovná:
). Potom sú hodnoty podielov vzorky 0,3667 a 0,2333. A rozdiel vzorky medzi nimi je rovný 0,1333, resp. Za predpokladu intervalu spoľahlivosti 95 % zistíme z tabuľky normálneho rozdelenia z cr = 1,96. kalkulácia štandardná chyba rozdiel vzorky je 0,0524. Nakoniec dostaneme, že spodná hranica 95% intervalu spoľahlivosti je 0,0307 a horná hranica je 0,2359. Získané výsledky možno interpretovať tak, že na každých 100 zákazníkov, ktorí získali zľavový kupón, môžeme očakávať od 3 do 23 nových zákazníkov. Treba však mať na pamäti, že tento záver sám o sebe neznamená efektívnosť využitia kupónov (pretože poskytnutím zľavy prichádzame o zisk!). Ukážme si to na konkrétnych údajoch. Predstierajme to priemerná veľkosť nákup je 400 rubľov, z toho 50 rubľov. je tam zisk obchodu. Potom sa očakávaný zisk na 100 zákazníkov, ktorí nedostali kupón, rovná:
50 0,2333 100 \u003d 1166,50 rubľov.
Podobné výpočty pre 100 kupujúcich, ktorí dostali kupón, uvádzajú:
30 0,3667 100 \u003d 1100,10 rubľov.
Pokles priemerného zisku na 30 sa vysvetľuje skutočnosťou, že pri použití zľavy kupujúci, ktorí dostali kupón, v priemere nakúpia za 380 rubľov.
Konečný záver teda naznačuje neefektívnosť používania takýchto kupónov v tejto konkrétnej situácii.
Komentujte. Tento problém je možné vyriešiť pomocou štandardných nástrojov StatPro. K tomu stačí znížiť túto úlohu na problém odhadu rozdielu dvoch prostriedkov istým spôsobom a potom aplikovať StatPro/Štatistická inferencia/Dvojvzorková analýza vytvoriť interval spoľahlivosti pre rozdiel medzi dvoma strednými hodnotami.
Kontrola intervalu spoľahlivosti
Dĺžka intervalu spoľahlivosti závisí od nasledujúcich podmienok:
priamo údaje (štandardná odchýlka);
úroveň významnosti;
veľkosť vzorky.
Veľkosť vzorky na odhad priemeru
Najprv sa zamyslime nad problémom všeobecný prípad. Označme hodnotu polovice dĺžky intervalu spoľahlivosti, ktorý nám bol daný ako B (obr. 104  ). Vieme, že interval spoľahlivosti pre strednú hodnotu nejakej náhodnej premennej X je vyjadrený ako
). Vieme, že interval spoľahlivosti pre strednú hodnotu nejakej náhodnej premennej X je vyjadrený ako ![]() , Kde
, Kde ![]() . Za predpokladu, že:
. Za predpokladu, že:
![]() a vyjadrením n dostaneme .
a vyjadrením n dostaneme .
bohužiaľ, presná hodnota nepoznáme rozptyl náhodnej premennej X. Okrem toho nepoznáme hodnotu t cr, pretože závisí od n prostredníctvom počtu stupňov voľnosti. V tejto situácii môžeme urobiť nasledovné. Namiesto rozptylu s používame nejaký odhad rozptylu pre niektoré dostupné realizácie skúmanej náhodnej premennej. Namiesto hodnoty t cr použijeme pre normálne rozdelenie hodnotu z cr. To je celkom prijateľné, pretože funkcie hustoty pre normálne a t-rozdelenie sú veľmi blízke (okrem prípadu malého n ). Požadovaný vzorec má teda tvar:
 .
.
Keďže vzorec dáva, všeobecne povedané, neceločíselné výsledky, za požadovanú veľkosť vzorky sa považuje zaokrúhlenie s nadbytkom výsledku.
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby manažér odhadol dopyt po ňom, náhodne plánuje vybrať určitý počet návštevníkov spomedzi tých, ktorí ho už vyskúšali, a požiada ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný počet bodov, ktoré nový produkt získa, a vykresliť 95 % interval spoľahlivosti tohto odhadu. Chce však, aby polovičná šírka intervalu spoľahlivosti nepresiahla 0,3. Koľko návštevníkov potrebuje na hlasovanie?
nasledovne:

Tu r ots je odhad zlomku p a B je daná polovica dĺžky intervalu spoľahlivosti. Nafúknutú hodnotu pre n možno získať pomocou hodnoty r ots= 0,5. V tomto prípade dĺžka intervalu spoľahlivosti nepresiahne nastavená hodnota V prípade akejkoľvek skutočnej hodnoty p .
Príklad
Nechajte manažéra z predchádzajúceho príkladu, aby odhadol podiel zákazníkov, ktorí preferujú nový typ produktu. Chce vytvoriť 90% interval spoľahlivosti, ktorého polovičná dĺžka je menšia alebo rovná 0,05. Koľko klientov by malo byť náhodne vybratých?
Riešenie
V našom prípade je hodnota z cr = 1,645. Preto sa požadované množstvo vypočíta ako  .
.
Ak by mal manažér dôvod domnievať sa, že požadovaná hodnota p je napríklad asi 0,3, tak dosadením tejto hodnoty do vyššie uvedeného vzorca by sme dostali menšiu hodnotu náhodnej vzorky, konkrétne 228.
Vzorec na určenie náhodné veľkosti vzoriek v prípade rozdielu medzi dvoma priemermi napísané ako:
 .
.
Príklad
Niektoré počítačové spoločnosti majú centrum služieb zákazníkom. IN V poslednej dobe zvýšil sa počet sťažností zákazníkov na zlú kvalitu služieb. Stredisko služieb zamestnáva prevažne dva typy zamestnancov: tých, ktorí majú málo skúseností, ale absolvovali špeciálne školenia, a tých, ktorí majú rozsiahle praktické skúsenosti, ale neabsolvovali špeciálne kurzy. Spoločnosť chce analyzovať sťažnosti zákazníkov za posledných šesť mesiacov a porovnať ich priemerné počty na každú z dvoch skupín zamestnancov. Predpokladá sa, že počty vo vzorkách pre obe skupiny budú rovnaké. Koľko zamestnancov musí byť zahrnutých do vzorky, aby sme získali 95 % interval s polovičnou dĺžkou nie väčšou ako 2?
Riešenie
Tu σ ots je odhad štandardnej odchýlky oboch náhodných premenných za predpokladu, že sú blízko. V našej úlohe teda musíme nejakým spôsobom získať tento odhad. Dá sa to urobiť napríklad takto. Pri pohľade na údaje o sťažnostiach zákazníkov za posledných šesť mesiacov si manažér môže všimnúť, že vo všeobecnosti existuje 6 až 36 sťažností na zamestnanca. S vedomím, že pre normálne rozdelenie nie sú prakticky všetky hodnoty väčšie ako tri štandardné odchýlky od priemeru, môže sa odôvodnene domnievať, že:
![]() , odkiaľ σ ots = 5.
, odkiaľ σ ots = 5.
Dosadením tejto hodnoty do vzorca dostaneme  .
.
Vzorec na určenie veľkosť náhodnej vzorky v prípade odhadu rozdielu medzi podielmi vyzerá ako:

Príklad
Niektoré spoločnosti majú dve továrne na výrobu podobných produktov. Manažér spoločnosti chce porovnať chybovosť oboch tovární. Podľa dostupných informácií je miera odmietnutia v oboch továrňach od 3 do 5 %. Predpokladá sa, že vytvorí 99 % interval spoľahlivosti s polovičnou dĺžkou nie väčšou ako 0,005 (alebo 0,5 %). Koľko produktov by sa malo vybrať z každej továrne?
Riešenie
Tu p 1ot a p 2ot sú odhady dvoch neznámych zlomkov odpadu v 1. a 2. továrni. Ak dáme p 1ots \u003d p 2ots \u003d 0,5, potom dostaneme nadhodnotenú hodnotu pre n. Ale keďže v našom prípade máme nejaké a priori informácie o týchto podieloch, berieme horný odhad týchto podielov, a to 0,05. Dostaneme
Keď sa niektoré parametre populácie odhadujú zo vzorových údajov, je užitočné poskytnúť nielen bodový odhad parametra, ale aj interval spoľahlivosti, ktorý ukazuje, kde môže ležať presná hodnota odhadovaného parametra.
V tejto kapitole sme sa oboznámili aj s kvantitatívnymi vzťahmi, ktoré nám umožňujú zostaviť takéto intervaly pre rôzne parametre; naučené spôsoby kontroly dĺžky intervalu spoľahlivosti.
Upozorňujeme tiež, že problém odhadu veľkostí vzoriek (problém návrhu experimentu) možno vyriešiť pomocou štandardné prostriedky Konkrétne StatPro StatPro/Statistical Inference/Sample Size Selection.
Súvisiace publikácie
-
 Aký je r obraz bronchitídy
Aký je r obraz bronchitídy
je difúzny progresívny zápalový proces v prieduškách, ktorý vedie k morfologickej reštrukturalizácii steny priedušiek a ...
-
 Stručný popis infekcie HIV
Stručný popis infekcie HIV
Syndróm ľudskej imunodeficiencie - AIDS, Infekcia vírusom ľudskej imunodeficiencie - HIV-infekcia; získaná imunodeficiencia...